

NVIDIA A30 Tensor Core GPU

NVIDIA A30® は NVIDIA Ampereアーキテクチャの Tensorコアとマルチインスタンス GPU (MIG)で、大規模な AI推論やハイパフォーマンスコンピューティング (HPC)アプリケーションといった多様なワークロードを安全に高速化します。
A30 搭載サーバは強力な演算能力や HBM2 大容量メモリ、毎秒 933GBのメモリ帯域幅、NVLinkによるスケーラビリティをもたらします。 NVIDIA InfiniBand、NVIDIA Magnum IO、RAPIDSオーブンソースライブラリスイート (RAPIDS Accelerator for Apache Spark を含む)との組み合わせにより、NVIDIAデータセンタープラットフォームは、かつてないレベルのパフォーマンスと効率で、巨大なワークロードに対応します。

ディープラーニング トレーニング
NVIDIA A30 Tensorコアと Tensor Float (TF32)を利用することで、NVIDIA T4と比較して最大 10倍のパフォーマンスをコード変更することなく得られます。さらに、Automatic Mixed Precisionと FP16の活用で 2倍の高速化が可能になり、スループットは合わせて 20倍に増えます。
NVIDIA NVLink、PCIe Gen4、NVIDIA Mellanox ネットワーキング、 NVIDIA Magnum IO SDKと組み合わせることで、数千の GPUまでスケールできます。
Tensor コアと MIGにより、A30はいつでも柔軟にワークロードを処理できます。要求がピークのときには本稼働で推論に使用し、オフピーク時には一部の GPUを転用して同じモデルを高速で再トレーニングできます。
AI トレーニング — V100 の 3倍、T4 の 6倍のスループット
BERT Large ファインチューニング、収束までの時間

ディープラーニング 推論
NVIDIA A30 には、推論ワークロードを最適化する画期的な機能が導入されています。FP64から TF32や INT4まで、あらゆる精度を加速します。GPUあたり最大 4つの MIGをサポートする NVIDIA A30では、安全なハードウェアパーティションで複数のネットワークを同時に運用でき、サービス品質 (QoS)が保証されます。また、スパース構造により数々の推論パフォーマンスの向上に加え、最大 2倍のパフォーマンスがもたらされます。
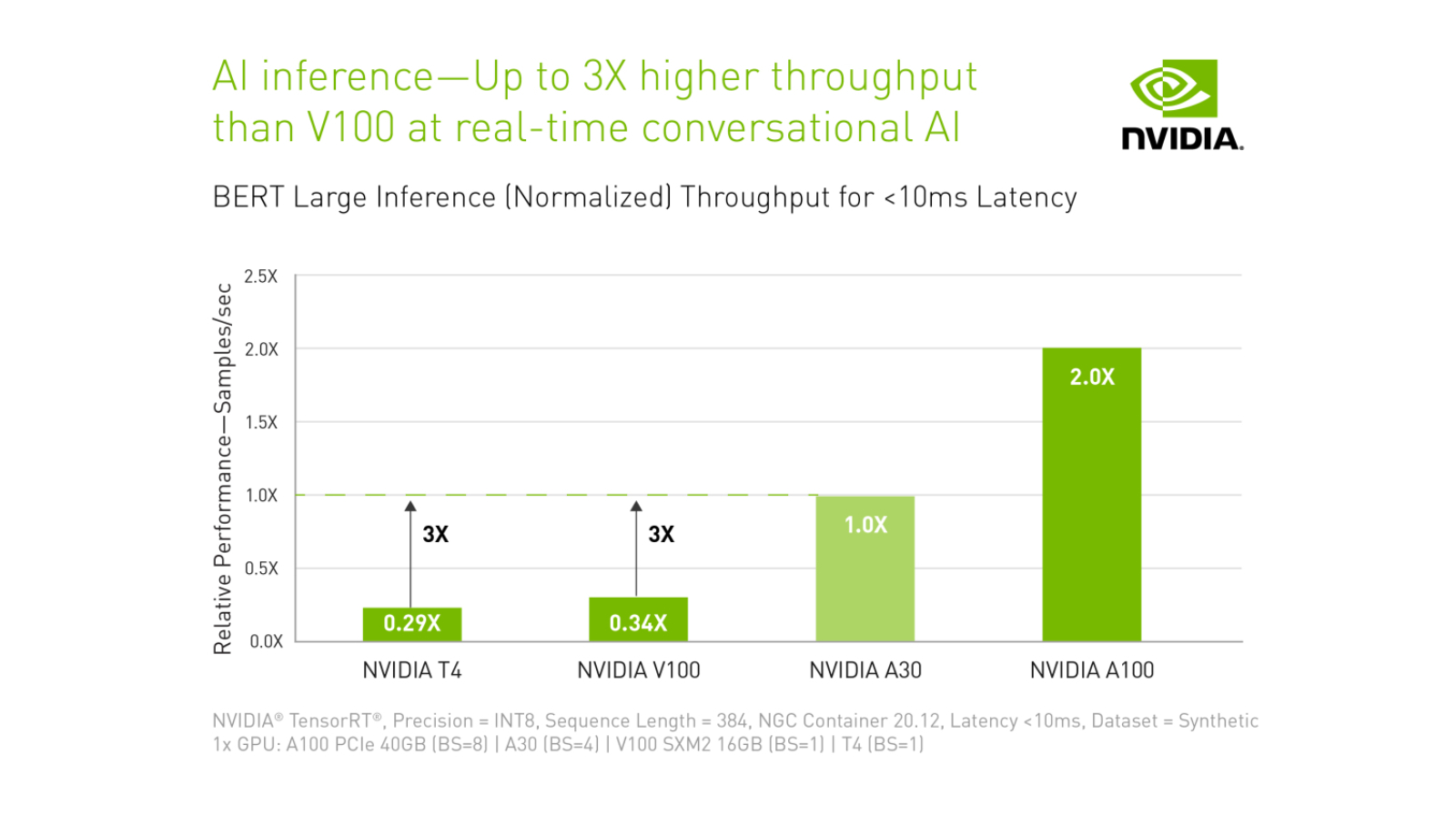
AI 推論 – リアルタイム対話型 AI で V100 と比較してスループットが最大 3倍
BERT Large 推論 (正規化済み)
レイテンシ 10ms 未満でのスループット
AIトレーニング— V100の 3倍、T4の 6倍のスループット
BRN50 v1.5推論 (正規化)
7ms以下のレイテンシでのスループット

ハイパフォーマンス コンピューティング
NVIDIA A30は FP64の NVIDIA Ampereアーキテクチャ Tensorコアを備えています。帯域幅が毎秒 933GB/sの GPUメモリ 24GBとの組み合わせにより、倍精度計算を短時間で解決できます。HPCアプリケーションで TF32を活用すれば、単精度の密行列積演算のスループットを上げることができます。
FP64 Tensorコアと MIGの組み合わせにより、研究機関は GPUを安全に分割して複数の研究者がコンピューティングリソースを利用できるようにし、QoSを保証し GPU使用率を最大限まで高めることができます。AIを展開している企業は要求のピーク時に NVIDIA A30を推論に利用し、オフピーク時には同じコンピューティングサーバを HPCや AIトレーニングのワークロードに転用できます。
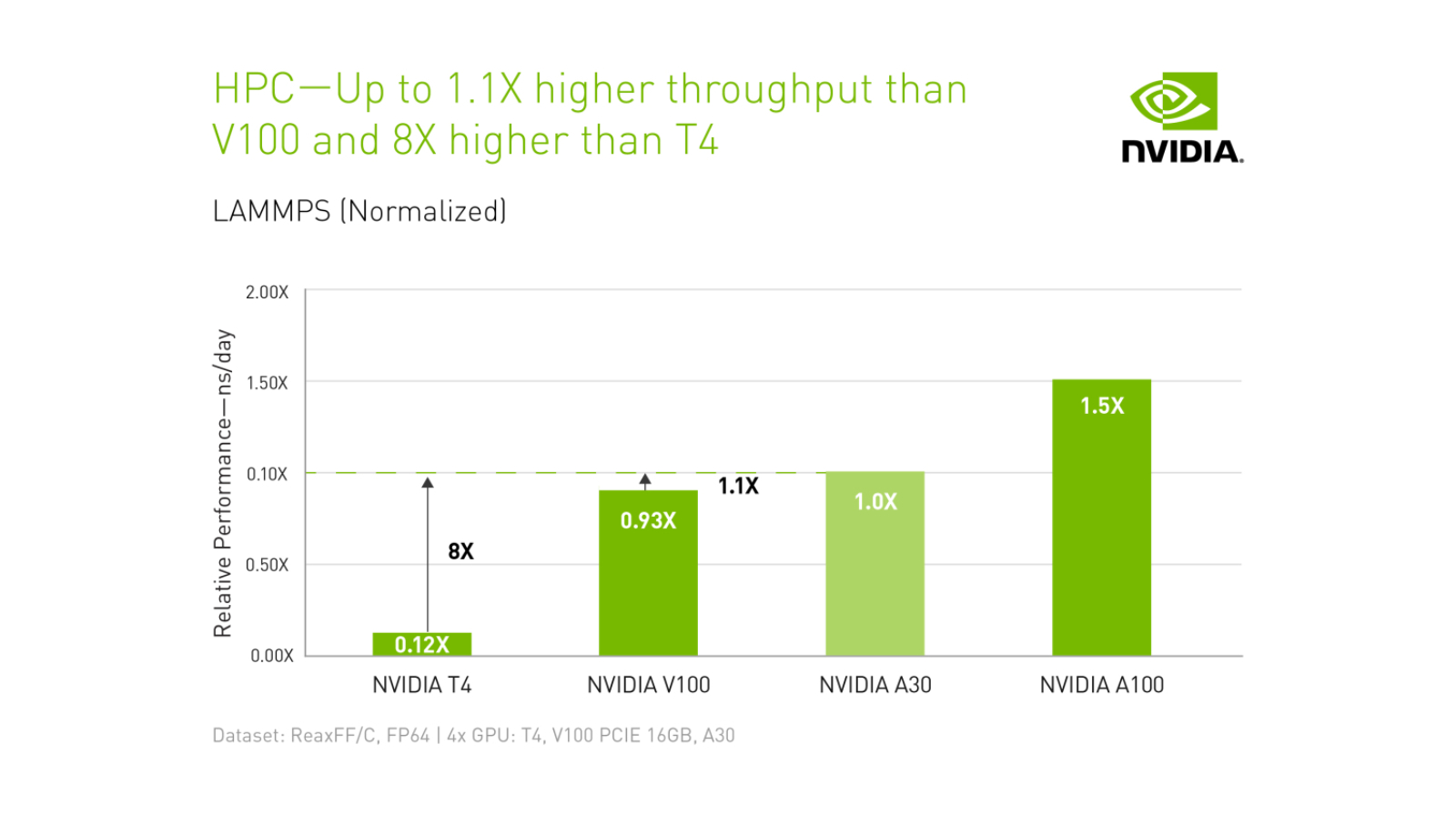
HPC — V100 と比較して最大 1.1 倍、T4 と比較して 8 倍のスループット
LAMMPS (正規化済み)
NVIDIA A30 datasheet

A30 / A100 仕様比較
| A30 | A100-PCIe | |
| FP64 | 5.2 teraFLOPS | 9.7 teraFLOPS |
| FP64 Tensor コア | 10.3 teraFLOPS | 19.5 teraFLOPS |
| FP32 |
10.3 teraFLOPS |
19.5 TFLOPS |
| TF32 Tensor コア | 82 teraFLOPS | 165 teraFLOPS* |
156 teraFLOPS | 312 teraFLOPS* |
| BFLOAT16 Tensor コア | 165 teraFLOPS | 330 teraFLOPS* |
312 teraFLOPS | 624 teraFLOPS* |
| FP16 Tensor コア | 165 teraFLOPS | 330 teraFLOPS* |
312 teraFLOPS | 624 teraFLOPS* |
| INT8 Tensor コア | 330 TOPS | 661 TOPS* |
624 TOPS | 1,248TOPS* |
| INT4 Tensor コア | 661 TOPS | 1321 TOPS* |
1,248 TOPS | 2,496 TOPS* |
| メディア エンジン | 1 optical flow accelerator (OFA) 1 JPEG デコーダー (NVJPEG) 4 ビデオ デコーダー (NVDEC) |
1 optical flow accelerator (OFA) 5 JPEG デコーダー (NVJPEG) 5 ビデオ デコーダー (NVDEC) |
| GPU メモリ | 24GB HBM2 | 40GB HBM2 |
| GPU メモリ帯域幅 | 933GB/s | 1,555GB/s |
| 相互接続 | PCIe Gen4: 64GB/s NVIDIA NVLINK: 200 GB/s** |
PCIe Gen4: 64GB/s NVIDIA NVLink 600 GB/s** |
| フォーム ファクター | Dual-slot, full-height, full-length (FHFL) |
Dual-slot, full-height, full-length (FHFL) |
| 最大熱設計電力 (TDP) |
165W | 250W |
| マルチインスタンス GPU (MIG) |
6GBのGPUインスタンスが4つ 12GBのGPUインスタンスが2つ 24GBのGPUインスタンスが1つ |
5GBのGPUインスタンスが7つ 10GBのGPUインスタンスが4つ 20GBのGPUインスタンスが2つ 40GBのGPUインスタンスが1つ |
* With sparsity
** NVLink Bridge for up to two GPUs
弊社では、科学技術計算や解析などの各種アプリケーションについて動作検証を行い、
すべてのセットアップをおこなっております。
お客様が必要とされる環境にあわせた最適なシステム構成をご提案いたします。