

NVIDIA A800 40GB Active

NVIDIA A800 40GB Active GPU は NVIDIA GV100 以来の高い FP64性能を持つアクティブクーリング GPUです。AIのデータトレーニングや推論にも高い性能を発揮し、エンドツーエンドソフトウェアプラットフォームである NVIDIA AI Enterpriseのサブスクリプション 3年間が付属しています。
搭載可能なワークステーションやサーバについてお気軽に担当営業までお問い合わせください。

NVIDIA A800 40GB Active GPU 特徴
HPC およびデータサイエンスワークロード向けの強力なパフォーマンスと多用途性
NVIDIA Ampere アーキテクチャ
前世代に比べて 2倍のトレーニングと推論の性能
倍精度コンピューティング
HPCアプリケーション向けのパワフルな FP64性能
第 3世代 NVLink
400GB/s 高速インターコネクト
超高速メモリー
40GB HBM2, 1.5TB/s BW
マルチインスタンス GPU (MIG)
分離された安全なマルチテナント
HPC とシミュレーションを強化
GPU アクセラレーションによりパフォーマンスと効率が大幅に向上
倍精度コンピューティング
HPC アプリケーション向けのパワフルな FP64機能
製品設計、製造、エネルギー、ヘルスケア
超高速メモリー
40GB HBM2, 1.5TB/s BW
第 3世代 NVLink
400GB/s 高速インターコネクト
HPC – GTC
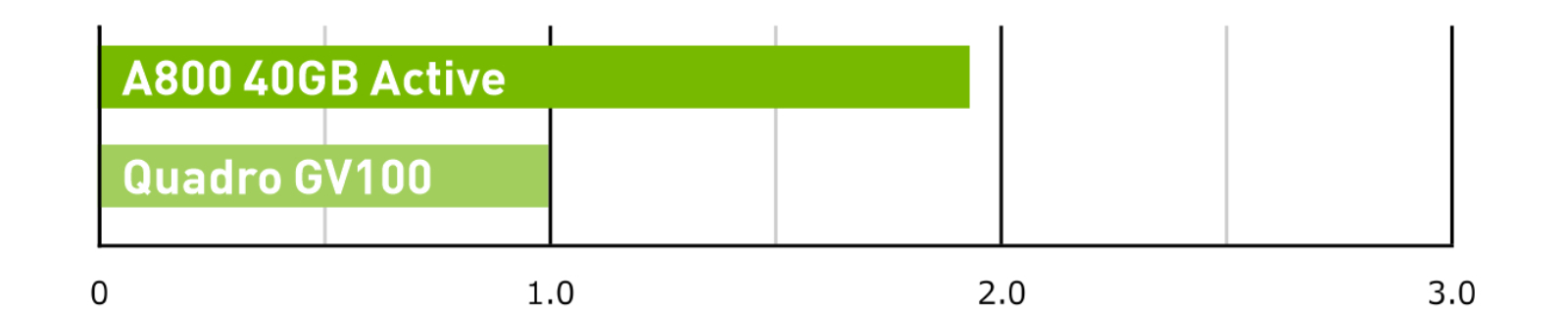
GTC Version 4.5, TAE, Precision=FP32.
HPC – LAMMPS
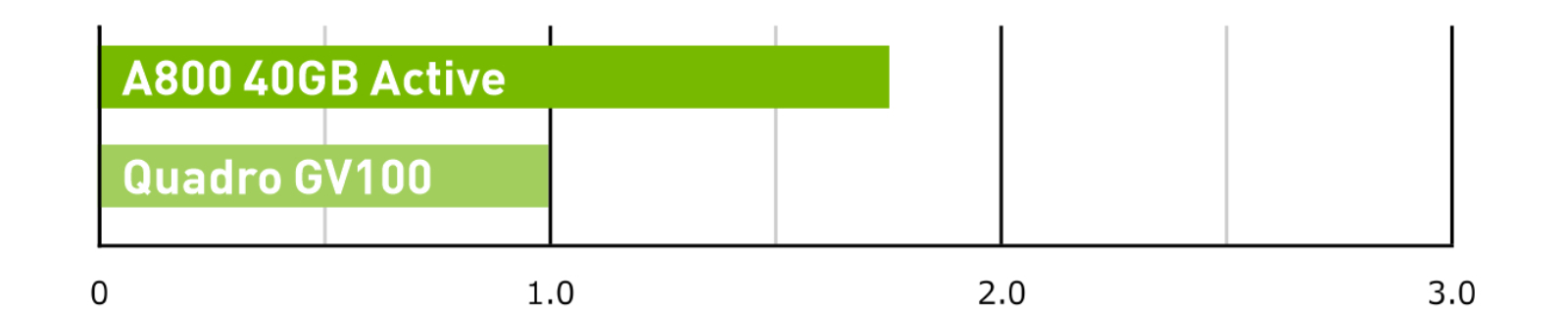
LAMMPS patch_8Feb2023, Atomic Fluid Lennard-Jones 2.5 (cutoff); Precision=FP64.
加速された AI機能
開発、トレーニングと推論
2倍のトレーニングと推論の性能
ワークステーションで実現する AI開発とトレーニングでの優れたパフォーマンスと規模
マルチインスタンス GPU (MIG)
コンピューティングリソースとメモリリソースを分割して使用率を最適化
初期規模の AI開発、小規模バッチ推論
3年間の NVIDIA AI Enterprise サブスクリプション
AIの開発と展開のためのクラウドネイティブソフトウェアスイート
AI Training – ResNet-50 V1.5
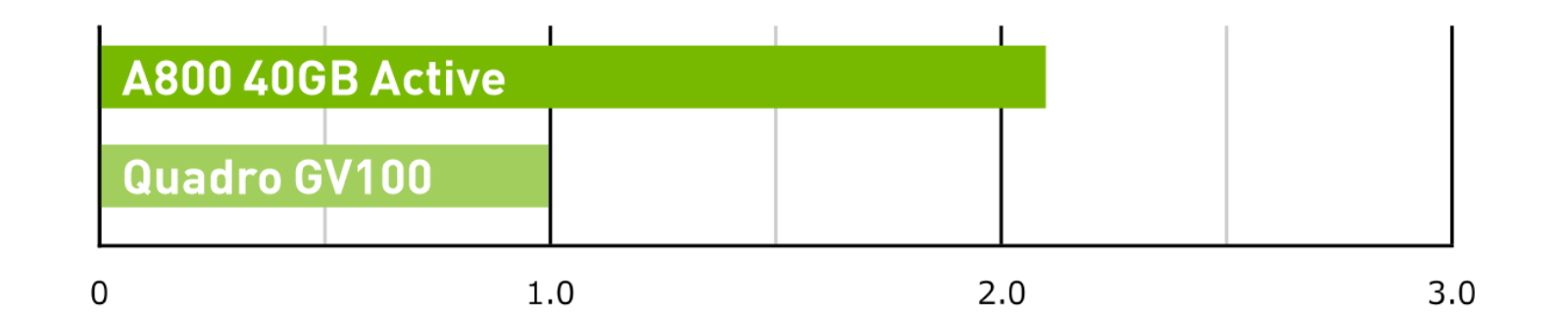
ResNet-50 V1.5 Training. Batch Size=256; Precision=Mixed.
AI Training – BERT – Large
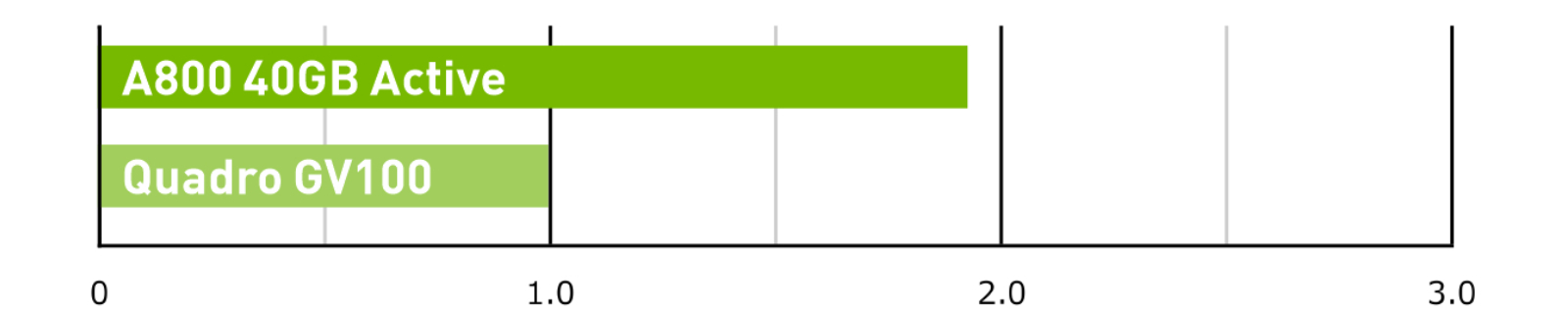
BERT Large Pre-Training Phase 2 Batch Size=8; Precision=Mixed.
AI Inference – ResNet-50 V1.5e
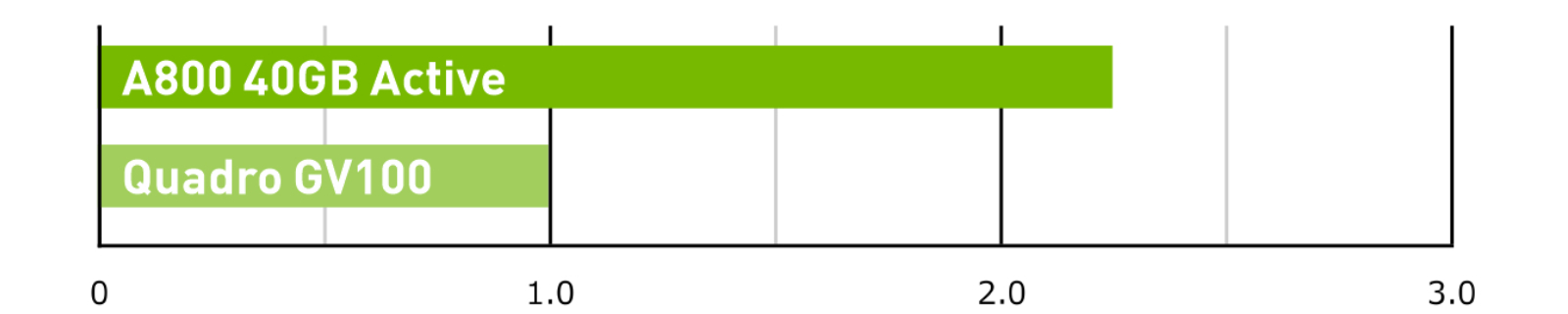
ResNet-50 V1.5 Inference. Batch Size=128; Precision=Mixed.
AI Inference – BERT – Large
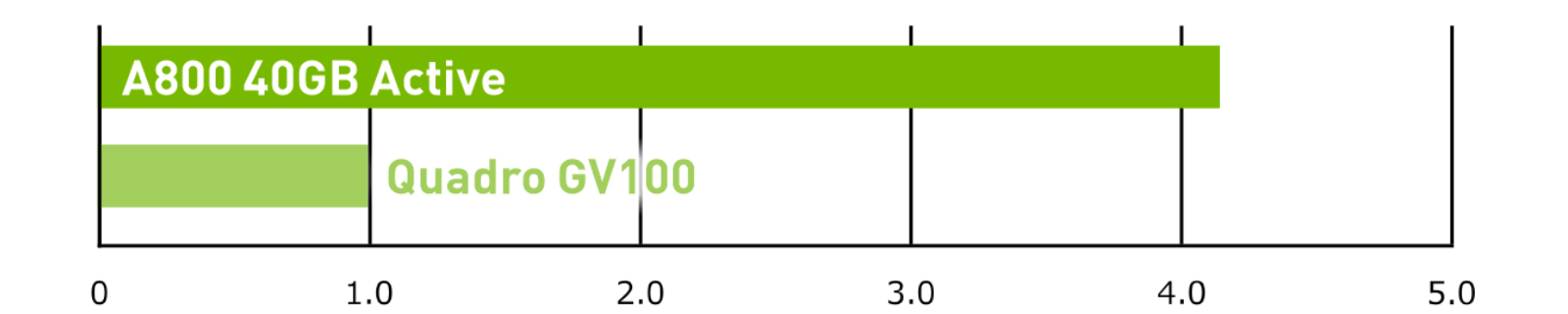
BERT Large Inference. Batch Size=128; Precision=INT8.
A800 40GB Active + NVIDIA AI Enterprise
3年間のサブスクリプションが付属

AI 対応プラットフォーム
- NVIDIA認定システムを使用したターンキー ソリューション
- 迅速な価値実現
- AIを活用したアプリケーションの大規模なエコシステム
- 迅速な実証実験 PoC
- サービスパートナーネットワーク
エンドツーエンドの AIソフトウェアスタック
- クラス最高の AIツールとフレームワーク
- AIドメインフレームワーク事前トレーニング済みモデル
- クラウドネイティブでアジャイル
- Kubernetes ベースのアプリケーション

高性能かつ高効率
- Transformer Engine による最速のトレーニング
- MIGにる最高の効率とセキュリティ
- NVIDIA Triton Inference Serverによる市場をリードする推論パフォーマンスの合理化

アジャイルでスケーラブル
- 幅広いユースケースを加速
- 1つのインフラストラクチャ上で AIパイプライン全体にサービスを提供する柔軟性
- 効果的なリソースの共有
- マルチ GPUおよびマルチノード構成に拡張

オープンかつエンタープライズ対応
- 実証済みのオープンソースから構築された、合理化されたエンタープライズ AI
- 世界中での NVIDIAサポートの保証
- 保証された応答時間
- 優先セキュリティ通知
NVIDIA AI Enterprise カタログ

NVIDIA A800 40GB Active データシート

NVIDIA A800 40GB Active / Quadro GV100 仕様比較
| A800 40GB Active | Quadro GV100 | |
| Architecture | Ampere | Volta |
| CUDA Cores | 6,912 | 5,120 |
| Tensor Cores | 432 | 640 |
| Single-Precision Performance | 19.5 TFLOPS |
14.8 TFLOPS |
| Double-Precision Performance | 9.7 TFLOPS | 7.4 TFLOPS |
| Peak Tensor Performance | 623.8 TFLOPS | 118.5 TFLOPS |
| Multi-Instance GPU | Up to 7 MIG instances @ 5GB | – |
| GPU Memory | 40GB HBM2 | 32GB HBM2 |
| Memory Band Width | 1555.2 GB/s | 870 GB/s |
| Memory Interface | 5120 bit | 4096 bit |
| NVIDIA NVLink | Yes | Yes |
| NVLink Bandwidth | 400 GB/s | 200 GB/s |
| Graphics Bus | PCIe Gen4 x 16 | PCIe Gen3 x 16 |
| Output | – | DP x4 |
| TDP | 240W | 250W |
弊社では、科学技術計算や解析などの各種アプリケーションについて動作検証を行い、
すべてのセットアップをおこなっております。
お客様が必要とされる環境にあわせた最適なシステム構成をご提案いたします。